How to Use Claude Agents: A Developer's Guide to Managed Agents, Sub-agents, and Real-time Data
A developer's guide to Claude Managed Agents, Claude Code sub-agents, and the Messages API. Setup in 4 steps, parallel execution, MCP, rate limits.
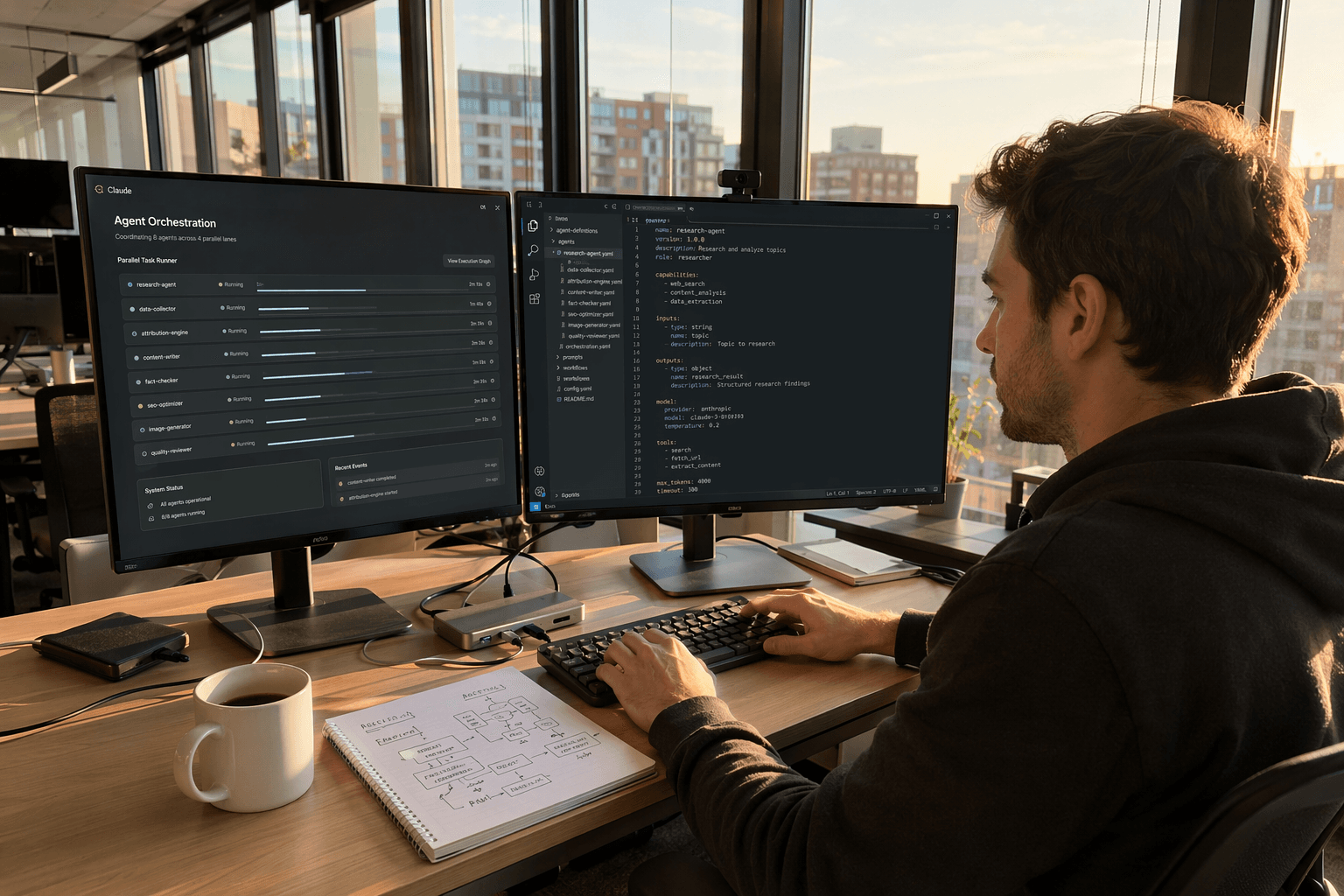
Claude agents are everywhere this quarter, but most tutorials treat them like a single feature. They are not. There is a Messages API loop you build yourself, a managed cloud harness Anthropic runs for you, and a sub-agent system inside Claude Code that spawns parallel workers from your terminal. Each has a different threat model, cost profile, and answer to the question developers actually ask: how do I get useful work out of this without burning my context window or my budget?
This guide walks through the three flavours in production order: pick the right surface, ship a first agent in four steps, wire it to real data, and avoid the failure modes that have turned into viral threads on Reddit and Hacker News. Everything here is taken from Anthropic's docs and verifiable community sources. Numbers you can act on.

What is the difference between Claude Managed Agents and the Messages API?
Anthropic ships two distinct ways to build with Claude, and treating them as interchangeable is the most common early mistake. The Messages API gives you direct, fine-grained access to the model. You write the agent loop, you handle tool execution, you run the infrastructure. It is the right choice when you have a runtime you trust.
Claude Managed Agents, released in beta in April 2026, is the opposite trade. Anthropic runs the container, the tool execution layer, the prompt caching, and the compaction logic. You bring an API key and a system prompt; the harness handles the rest. Per the official overview, the four core concepts are Agent, Environment, Session, and Events. An Agent is the model plus its system prompt, tools, MCP servers, and skills. An Environment is the container template. A Session is a running instance. Events are messages exchanged between your application and the agent over server-sent events.
The practical rule: choose Messages API for control, choose Managed Agents for autonomy. If your task is short and deterministic, write the loop. If it is long-running, stateful, and needs to survive your application restarting, use the harness. A harness, not a handwritten loop.
How do you create your first Claude agent in four steps?
The Anthropic quickstart reduces the first-agent journey to four concrete actions, and you can complete all of them via the ant CLI without writing a line of code.
Step one: create the agent. Run ant beta:agents create with flags for name, model, system prompt, and tools. The agent is a reusable definition; you create it once and reference its ID across many sessions. Step two: create an environment, the cloud container template, configured with network rules and any required packages. Step three: start a session, passing both the agent ID and the environment ID. Step four: send a user event and stream the response. The beta header managed-agents-2026-04-01 is required on every request, though the SDK sets it for you.
The tool declaration to remember is agent_toolset_20260401. Adding this single tool type to your agent enables the full built-in set: Bash, file operations, web search and fetch, and MCP server connections. You do not have to enumerate each capability separately. According to Anthropic's documentation, beta access is enabled by default for all API accounts, which means the entire flow above is unlocked the moment you have a key.
What tools and built-in capabilities do Claude agents support?
The official tools reference lists four built-in capability families. Bash gives the agent a shell inside its container. File operations cover read, write, edit, glob, and grep, which together turn the container into a workspace the model can navigate the way a developer would. Web search and fetch use Anthropic's managed search rather than unrestricted crawling, which matters when you start reasoning about what the agent can and cannot reach. The fourth family is MCP, the Model Context Protocol, which is the open standard for connecting agents to external tools and data sources.
MCP is the part most teams underweight. The built-in tools are powerful, but they are also bounded. Web search returns indexed pages, not Reddit threads or X posts. File operations live inside the sandboxed container. The moment your agent needs anything outside that perimeter (a private database, a vector index, or live platform data), you add an MCP server. The harness handles the connection lifecycle and tool advertising; the model decides when to call.
That is the lever that separates a toy agent from a useful one. A research agent without external tools can only summarise what it already knows. A research agent with the right MCP servers can read what people are saying right now.
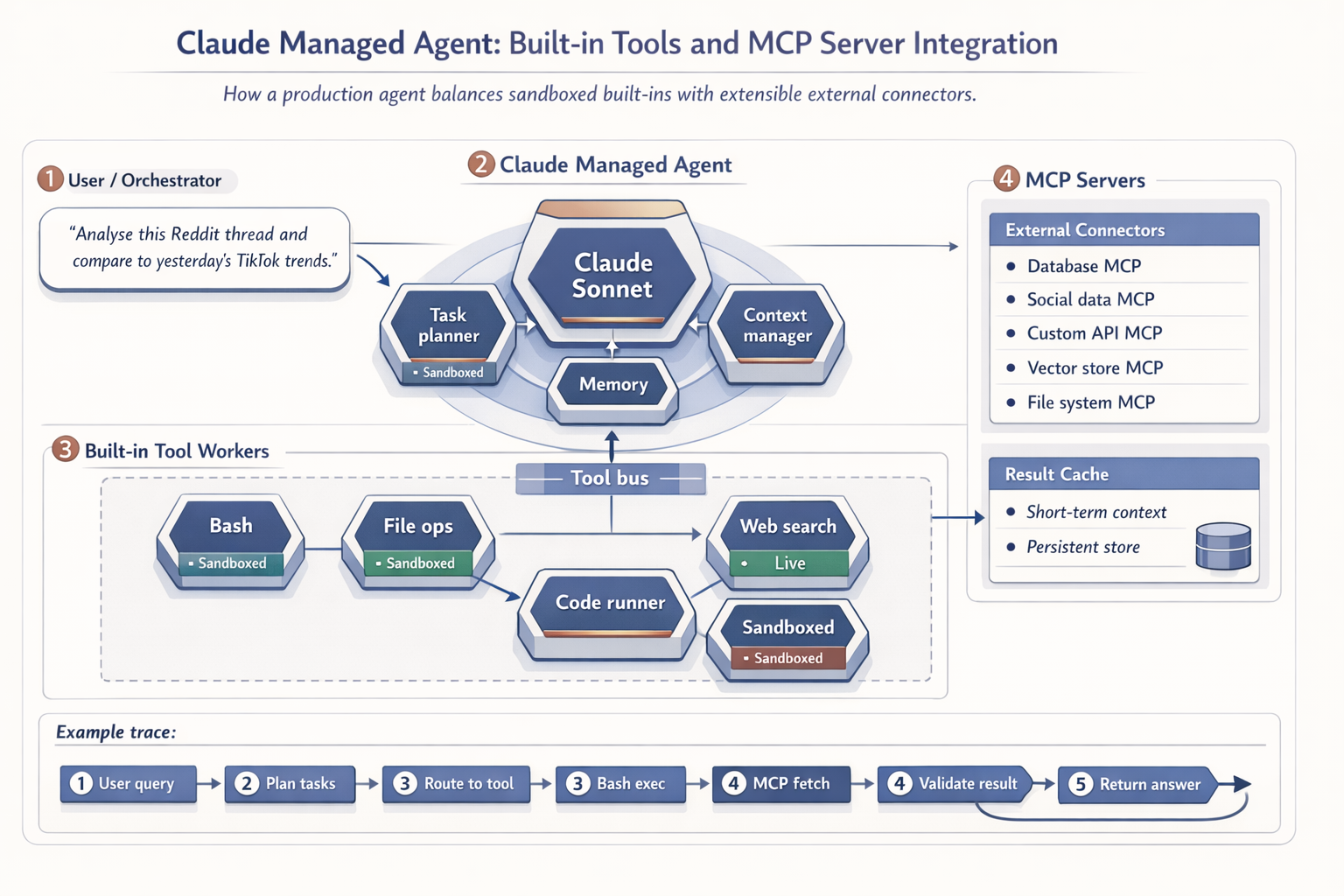
How do you run multiple Claude agents in parallel without burning through context?
Claude's context window holds up to 200,000 tokens, equivalent to roughly 150,000 words or a 500-page book according to Anthropic's overview. That sounds like a lot until you watch a single agent run six sequential web searches and consume a quarter of it in fifteen minutes. The fix is structural: stop running everything in one context, and start delegating.
Claude Managed Agents supports multi-agent sessions, currently in research preview beta, where Claude orchestrates sub-agents in parallel and each carries its own context window. Inside Claude Code, the Product Talk guide to Claude Code features covers the equivalent pattern: spawning sub-agents via the Task or Explore tools so that researching three competitors does not pollute the main session with three sets of raw search results. The sub-agent reports back with a summary; the main context stays clean.
Parallel agents are faster but more expensive in tokens. Product Talk notes that a Claude Pro user running fifteen parallel sub-agents can exhaust their usage limit rapidly. The rule of thumb from Hacker News threads on parallel agents: use parallelism when the tasks are independent, use serial execution when they share state, and put your highest-value reasoning in the main session rather than in a sub-agent that will report a summary back through a narrow pipe.
How do you give a Claude agent access to real-time social data?
Built-in web search returns pages, not posts. That is fine for evergreen reference material and broken for anything time-sensitive. A Claude agent asked to summarise developer reaction to a new API release will get SEO articles written 48 hours later, not the Hacker News thread that ran the day of the launch. The walled-garden platforms (Reddit, X, TikTok, HN) are exactly the sources with the highest signal, and they are the sources generic crawlers cannot reach.
The integration pattern that has stabilised is to connect a purpose-built MCP server. SocialCrawl ships one as npx -y socialcrawl-mcp. Add it to your Claude Managed Agent's MCP configuration and the agent gains access to 43 platforms and 321 endpoints through a single unified schema. Reddit posts, X threads, HN discussions, TikTok videos, Polymarket contracts, and YouTube transcripts come back in the same response envelope. No per-platform authentication, no per-platform rate limits, no twelve separate tool definitions.
That changes the answer your agent can give. A Claude agent without social data sources returns paragraphs that read like an editorial summary. A Claude agent with them returns opinions, not webpages. People, not pages. The contrast shows up immediately in the first piece of work a stakeholder asks the agent to do, usually competitive research before a meeting. A research subagent that can read the actual 35,902-upvote Reddit thread on a competitor outage (cited in SocialCrawl's Reddit search for "claude agents tutorial") writes a different brief than one that cannot.
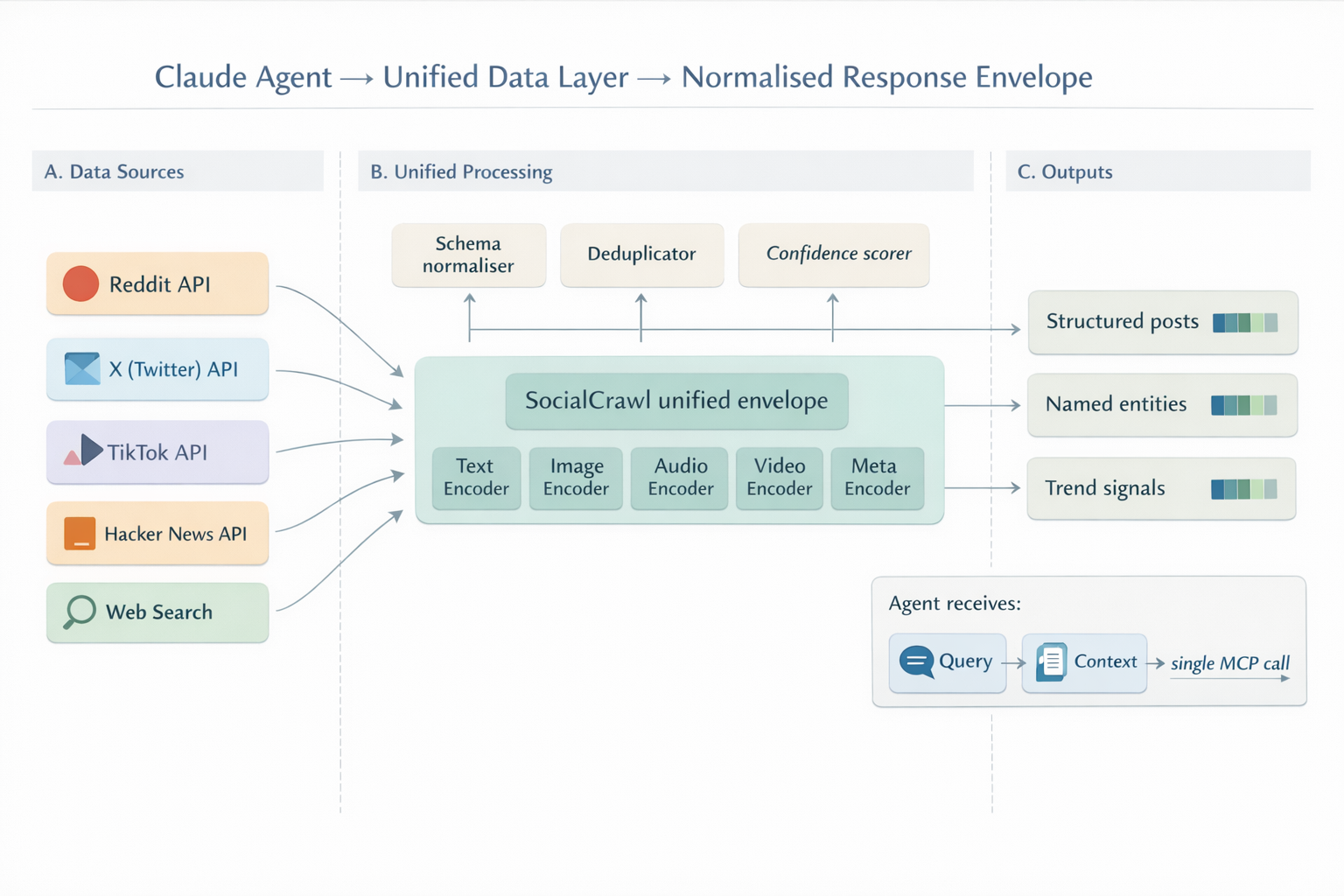
What are the rate limits and cost considerations for production Claude agents?
Anthropic publishes hard numbers for the Managed Agents API. The overview page documents 300 create requests per minute across agents, sessions, and environments, and 600 read, list, and stream requests per minute. Those ceilings are generous for prototyping and tight enough to force discipline in production, which is the right level for a managed beta.
Token cost dominates the bill. With a 200,000-token context and parallel sub-agents each carrying their own window, a poorly designed workflow can multiply token consumption by ten or more in an afternoon. The harness provides prompt caching and automatic compaction per Anthropic's overview. The mitigations you add yourself are tighter system prompts, narrower tool scopes, and explicit instructions that sub-agents return summaries rather than raw transcripts. If your sub-agent dumps 40,000 tokens of search results, the parent context holds the bill.
On observability: session event history is persisted server-side and can be fetched in full at any point, per the Anthropic quickstart. Treat that as your production log. Before scaling an agent up, wire its event stream into the same telemetry pipeline you use for any other service.
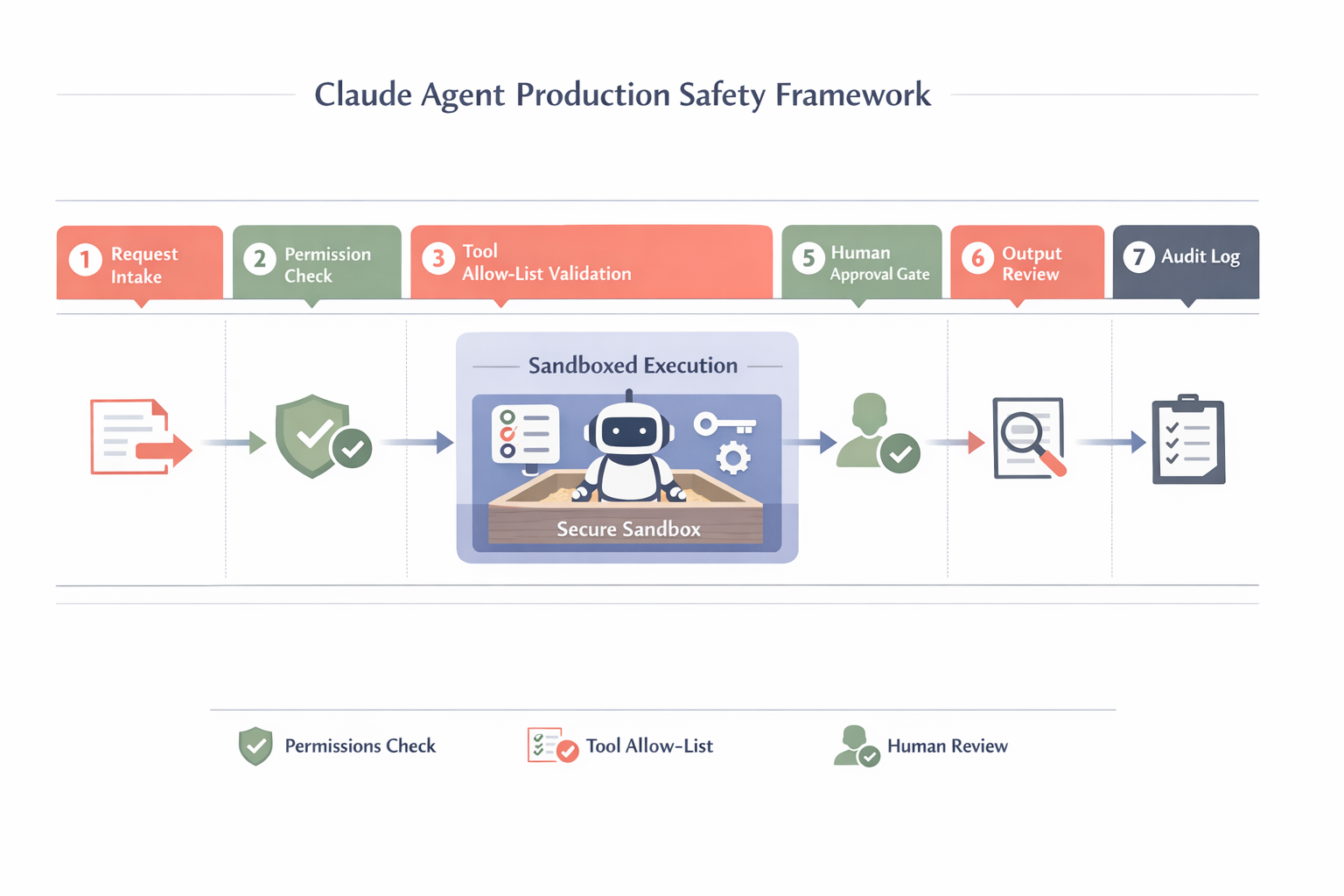
What goes wrong when Claude agents act without proper permissions?
A Reddit post titled "Claude-powered AI coding agent deletes entire company database in 9 seconds" earned 35,902 upvotes and 2,759 comments according to SocialCrawl's Reddit search, making it the highest-scored social post for the term "claude agents tutorial" on the day this article was researched. The agent did exactly what it was told to do; the problem was that it was told too much and constrained too little.
The permissions model for Claude Managed Agents is opt-in by design. The container has a Bash tool, file operations, and any MCP servers you add. Production safety is not a feature you toggle; it is a set of choices you make. Run the agent in an environment without database credentials. Scope MCP servers to read-only where possible. Use the session event stream to require human approval for any tool call that mutates external state. The harness will not stop the model from issuing a DROP TABLE; your environment configuration is what stops the agent from reaching a database where that command would matter.
The Product Talk guide makes the same point in a different register: the Claude Code sub-agent system stores user-defined sub-agents as markdown files in ~/.claude/agents or project/.claude/agents, and those definitions can include explicit tool allow-lists. If a sub-agent only needs to read files, do not give it Bash. The pattern is identical across surfaces: principle of least privilege, enforced at agent definition time, not at runtime.
When should you choose Claude Managed Agents over LangChain, CrewAI, or AutoGen?
The alternatives are mature and the comparison is not one-sided. LangChain remains the broadest framework for stitching together LLMs, tools, and memory across providers. Microsoft's AutoGen and CrewAI both offer first-class multi-agent orchestration that predates Claude's native multi-agent support. If your stack already uses one of them, the migration cost is real and the differentiation is narrower than the marketing suggests.
What Claude Managed Agents actually sells is reduced operational burden. You do not run the container. You do not maintain the agent loop. You do not write retry logic for tool calls or compaction logic for long contexts. The Model Context Protocol is the same standard regardless of which framework you use, so MCP servers you build for LangChain or CrewAI plug into Claude Managed Agents unchanged. The lock-in is lower than it looks; the operational saving is higher than it sounds.
A practical decision rule: if your agent runs for under a minute inside an existing service, the Messages API plus your current framework is the cheaper answer. If it runs for thirty minutes and orchestrates four sub-agents through a tool chain that includes social data and a private database, the harness is doing work you would otherwise pay an engineer to maintain. Production autonomy, not framework purity, is what you are buying.
Frequently asked questions
What is the beta header required for Claude Managed Agents?
Every API request must include managed-agents-2026-04-01. The official SDKs set this automatically, so the requirement only matters if you are calling the API directly with curl or an HTTP client.
Can I define a sub-agent that only runs certain tools?
Yes. User-defined sub-agents in Claude Code are markdown files with front matter stored in ~/.claude/agents or project/.claude/agents, and the front matter supports tool allow-lists. In Claude Managed Agents, you scope tools at the Agent definition step rather than at runtime.
How do I avoid filling the 200,000-token context window? Delegate research-heavy work to sub-agents, instruct them to return summaries rather than raw results, and rely on the harness's built-in compaction. Keeping the highest-value reasoning in the main session and pushing wide search into parallel sub-agents is the dominant pattern that has emerged in Hacker News threads on parallel Claude agents.
Does Claude Managed Agents support webhooks? Yes. The harness is designed for asynchronous, long-running workloads, and sessions can be driven by external events including webhook triggers. Session event history is persisted server-side so you can reconstruct any run after the fact.
How do I add real-time social data without writing a custom integration?
Configure an MCP server in your agent definition. For social data specifically, npx -y socialcrawl-mcp exposes 43 platforms and 321 endpoints through one schema, so the agent gets Reddit, X, HN, TikTok, YouTube, and the rest behind a single tool surface. Time to first data is under a minute.
Related posts

Naver Crawling in 2026: Blog, Cafe, and News via API
Three ways to crawl Naver in 2026: the official Naver Search Open API, your own HTML crawler, or one call to a unified API like SocialCrawl. Blog, cafe, news, and shopping, with code.

Python Social Media Crawling in 2026
Two ways to crawl social data with Python in 2026: build it yourself with requests and BeautifulSoup, or call a unified API with one httpx.get(). Here is when each one wins.

Best Time to Post on Social Media: 401 Posts Analyzed
Best time to post on social media: we analyzed 401 posts across TikTok, Instagram, YouTube, and Reddit. Posts at 20:00 UTC score +52% above the average.