Browse AI Web Scraper: Where It Wins, and Where Social Data APIs Fit Better
Browse AI is great for web pages; social platforms need a specialist. Decision guide for developers choosing scrapers vs unified social-data APIs.

Browse AI has earned its place. Over 500,000 users have built point-and-click robots on top of it, billions of records have flowed through the platform, and its G2 score sits at 4.7 out of 5 (Thunderbit review). When the job is "watch this product page and tell me when the price moves", it is hard to beat.
This article is a decision guide, not a takedown. Browse AI is built for web pages. Social platforms are not web pages. They are engagement-ranked conversation graphs guarded by anti-bot measures, rate caps and authentication walls. If a meaningful slice of your data lives inside Reddit threads, TikTok comments, X replies or Instagram captions, Browse AI alone will leave you patching robots every few weeks. The alternative is to keep Browse AI for what it does well and pair it with a specialist that opens the walled gardens.
By the end you should know which tool belongs in which slot of your stack.
What is Browse AI and what is it actually built for?
Browse AI launched in 2021 out of Vancouver with a clear premise: anyone should be able to extract data from the web without writing code. You record yourself clicking through a page, the platform learns the pattern, and a robot replays it on a schedule. The pre-built library covers more than 200 sites including Amazon, LinkedIn, Indeed, Yelp, Reddit, TikTok, YouTube and Instagram (browse.ai).
The strengths are real. In one head-to-head test, configuring a 10-field extraction on a static site took under four minutes, faster than every developer-centric alternative tested (Octoparse comparison). Integrations with 7,000+ apps via Zapier and direct webhooks mean the data lands wherever your workflow already lives. SOC 2 Type II and GDPR compliance are in the box.
What Browse AI is built for, in one line: monitoring structured information on stable web pages and routing it into business workflows. Pricing pages, e-commerce listings, job boards, competitor changelogs. Pages that load, render and stay roughly the same shape from one week to the next.
What it is not built for is the rest of this article.
Where does Browse AI hit its limits when you need social data?
Three pain points show up repeatedly in user reviews and head-to-head tests.
The first is volume economics. Browse AI's Professional plan costs $99 per month on annual billing for 5,000 credits, roughly 50,000 extracted rows (Browse AI pricing). Sounds generous until you try paginating 100 Reddit threads of 200 comments each. Reviewers have documented exhausting a Professional plan in a single day of heavy social scraping. The credit model punishes the deep, paginated, comment-tree work that social data actually requires.
The second is anti-bot fragility. Browse AI's robots are browser-automation, mimicking a user clicking through pages. That works on a Yelp listing. It works less well on TikTok, where layout changes ship weekly and rate-limit counters sit behind every request. Trustpilot's score for Browse AI is 3.2 out of 5, with frustrations clustering around volume limits and reliability rather than core functionality.
The third is schema fragmentation. A robot trained on a Reddit thread returns one shape. A robot trained on a TikTok video page returns another. A robot for X profiles returns a third. Feeding all three into the same downstream pipeline means custom normalisation code per source and four breakage paths every time a platform reshuffles its DOM.
These are the predictable consequences of using a generalist tool on platforms that punish generalists.
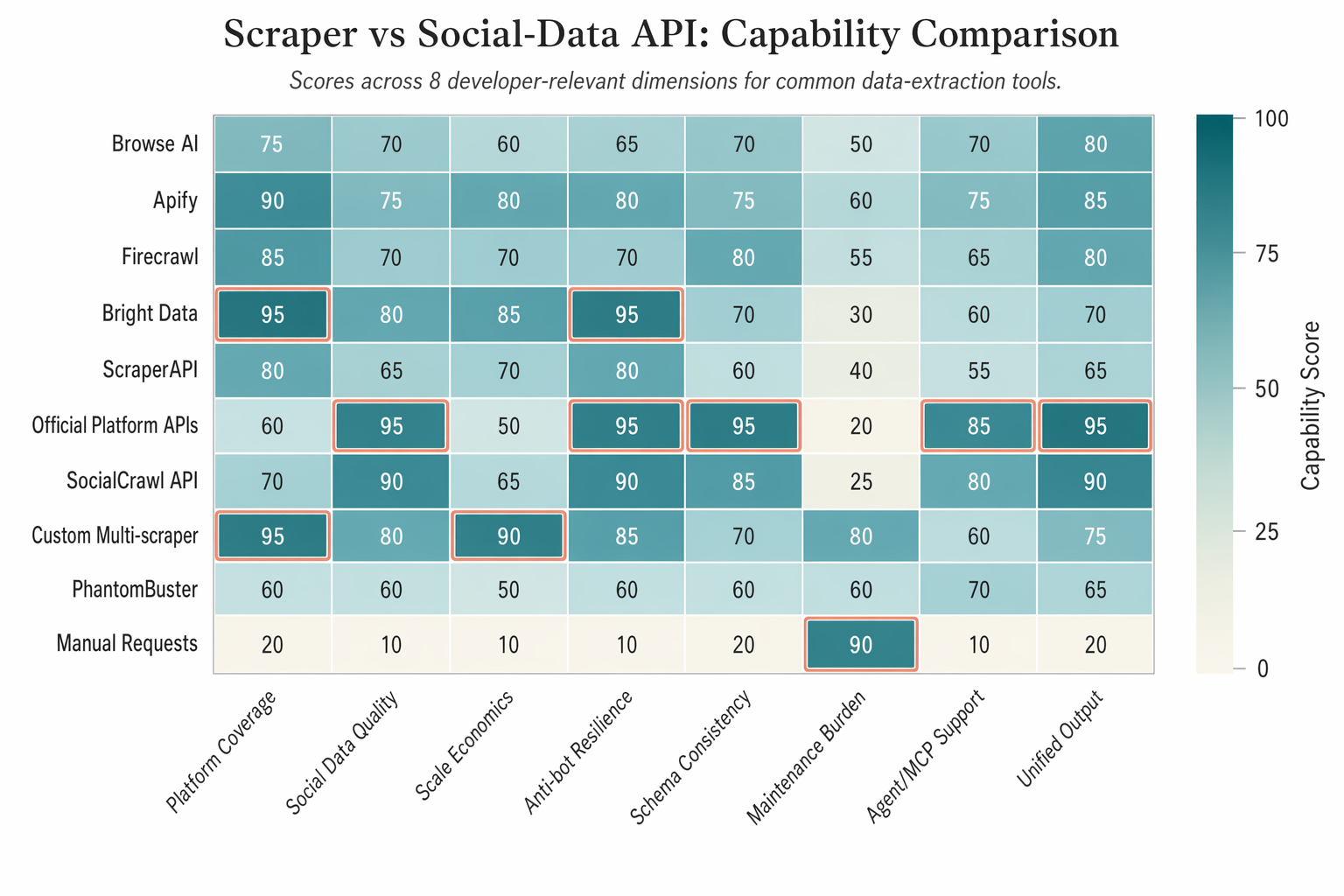
How does a social-data API differ from a general web scraper?
A general web scraper takes a URL and gives you what is on the page. A social-data API takes a query and gives you structured records that match a schema, regardless of which platform they came from.
The contract is different. With Browse AI, you are renting a configurable robot. With a social-data API, you are calling an endpoint that has already solved authentication, proxy rotation, schema normalisation and pagination for the specific platform. SocialCrawl, for example, ships 321 endpoints across 43 platforms, with Instagram alone covered by 30 endpoints — more than any other platform in the catalogue (socialcrawl.dev/developers).
The output is different too. A scraper returns HTML or generic markdown. A purpose-built social API returns a unified envelope with computed fields like engagement_rate, estimated_reach, content_category and language already filled in, ready to land in a database or feed into an LLM without extra parsing work.
The framing matters. This is opinions, not webpages. The product page says "best in class". The 2,200-upvote Reddit thread says something different. A scraper returning the product page misses the conversation entirely.
Is Browse AI good for scraping Reddit at scale?
Browse AI ships a pre-built Reddit robot, so for a few hundred posts a month from a handful of subreddits, it works. For production scale, the maths gets uncomfortable.
Reddit's OAuth API caps authenticated apps at 100 queries per minute and limits free-tier retrieval to roughly 1,000 records per query. Unauthenticated requests drop to 10 QPM (data365 on Reddit limits). Browse AI robots live inside those constraints whether they hit the API or scrape the page. Add the credit cost — a deep paginated thread can chew through a $99 plan in one run — and the unit economics for "all comments on every trending r/MachineLearning thread for the last week" stop working.
A purpose-built Reddit endpoint inside a social-data API handles the auth pool, rotates the proxies and returns structured comment trees with author, engagement and metadata fields already populated. SocialCrawl exposes seven Reddit endpoints under a single key.
The point is not that Reddit scraping is impossible with Browse AI. It is that the specialist tooling exists for a reason, and the cost curves cross quickly once volume climbs past a few thousand records per month.
Can Browse AI handle TikTok and Instagram reliably?
Less reliably than its catalogue suggests, and the reason is structural rather than a Browse AI shortcoming.
TikTok's Research API is gated behind academic approval, allows roughly 100 requests per day at basic tiers, and has been documented failing metadata retrieval for a notable share of videos (ResearchGate study on TikTok's Research API). The Business Display API caps basic tiers at around 100 requests per day. There is no high-volume official lane for the comment, hashtag and trend data that agent builders need.
Instagram is no easier. Firecrawl, a respected developer-focused scraper, explicitly blocks scraping on Instagram, YouTube and TikTok because of legal exposure (ScrapeCreators on Firecrawl restrictions). That is a deliberate decision by a serious team and tells you something about the problem.
Browse AI's TikTok and Instagram robots pull public data, but they sit on top of the same DOM and the same anti-bot defences. When TikTok ships a layout change on a Tuesday, the robot breaks on the Tuesday. A specialist API absorbs that maintenance centrally. SocialCrawl's TikTok coverage runs to 26 distinct endpoints for exactly this reason.
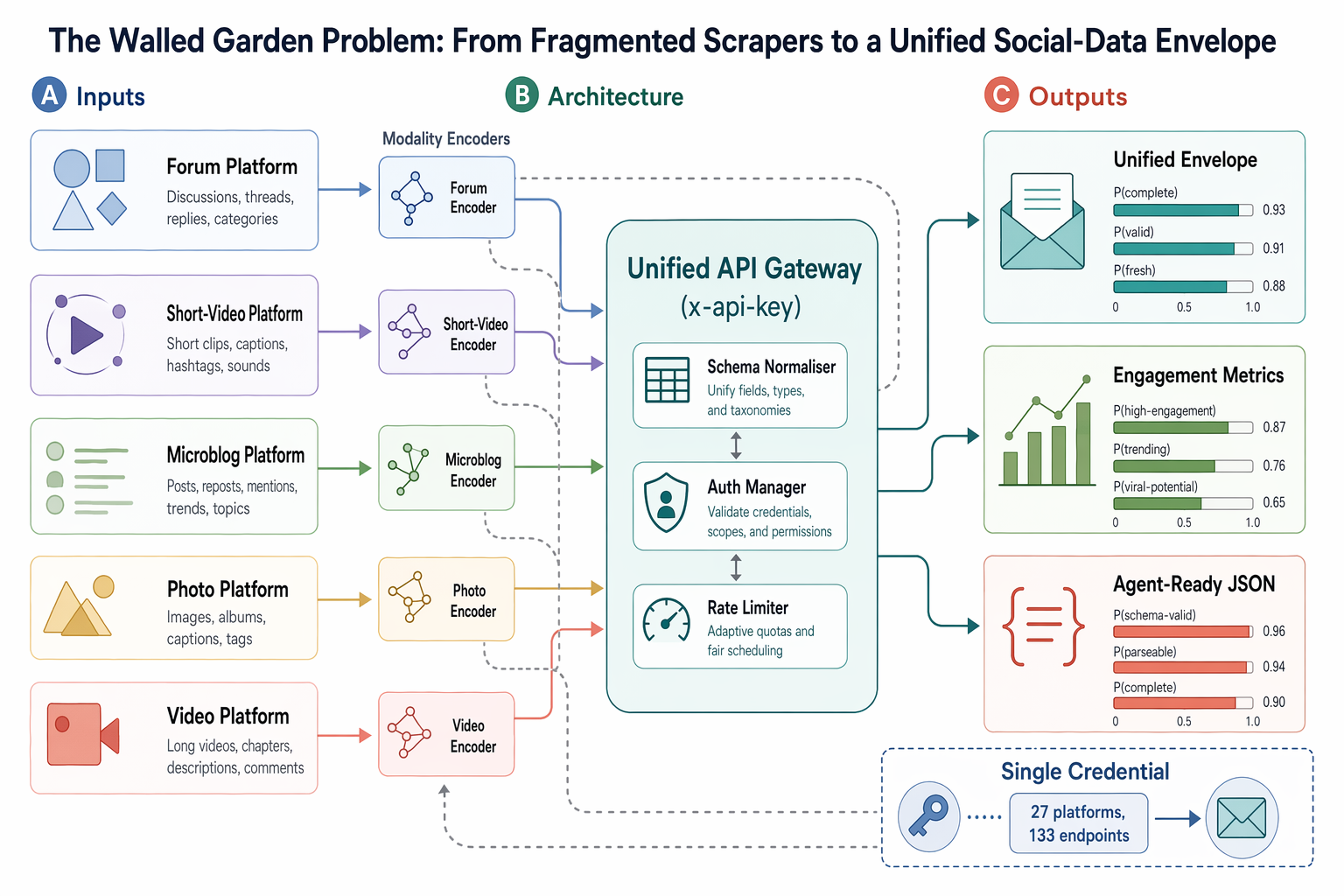
What does a unified social-data envelope actually save you?
Time, code and breakage, in that order.
Stitch together your own multi-platform pipeline with individual scrapers and you end up writing four normalisers, managing four sets of credentials, monitoring four anti-bot evolutions and shipping four different data contracts to the rest of your stack. Each is its own maintenance cycle.
A unified envelope collapses that to one. Every response arrives with the same shape: a success flag, the source platform, and content, author, engagement and metadata blocks. Engagement rate and estimated reach are computed on the way out. The downstream code that ingests a Reddit comment is the same code that ingests a TikTok caption.
One schema, every platform, not four schemas glued together. For an LLM-fed pipeline doing sentiment scoring, trend detection or training data assembly, that consistency removes an entire category of glue work. SocialCrawl's universal search endpoint queries 12 platforms in parallel for 20 credits per call, returning results ranked by engagement rather than SEO authority — equivalent to running 12 separate API calls in a single request (socialcrawl.dev/pricing).
When should you pair Browse AI with a specialist social API?
Most of the time. Browse AI is the right tool for general web monitoring. A social-data API is the right tool for social platforms. They are additive, not competitive.
A useful way to draw the line is to ask what share of your data need lives behind walled gardens. If you need pricing pages, competitor changelogs, job listings, review sites, public directories and the data is on stable rendered HTML, Browse AI carries the load. If you need Reddit threads, TikTok comments, X replies, YouTube transcripts, Instagram captions, HN debates or Polymarket odds — anything where the value is in the conversation rather than the page — a specialist takes that lane.
Concrete pairings that work in practice: a competitive-intelligence pipeline uses Browse AI to monitor a competitor's pricing pages and a social-data API to surface complaints in 1,500-upvote Reddit threads before a sales call. A launch-monitoring pipeline uses Browse AI to watch a changelog and a social-data API to capture the X threads, Reddit posts and TikTok videos that surface once news breaks. A training-data pipeline uses Browse AI for static forum and review pages and a social-data API for structured posts from Reddit, HN, TikTok and X arriving in a unified shape, ready for LLM ingestion without custom parsers.
The framing is simple: people, not pages. Browse AI tells you what a page says. A social-data API tells you what people are saying.
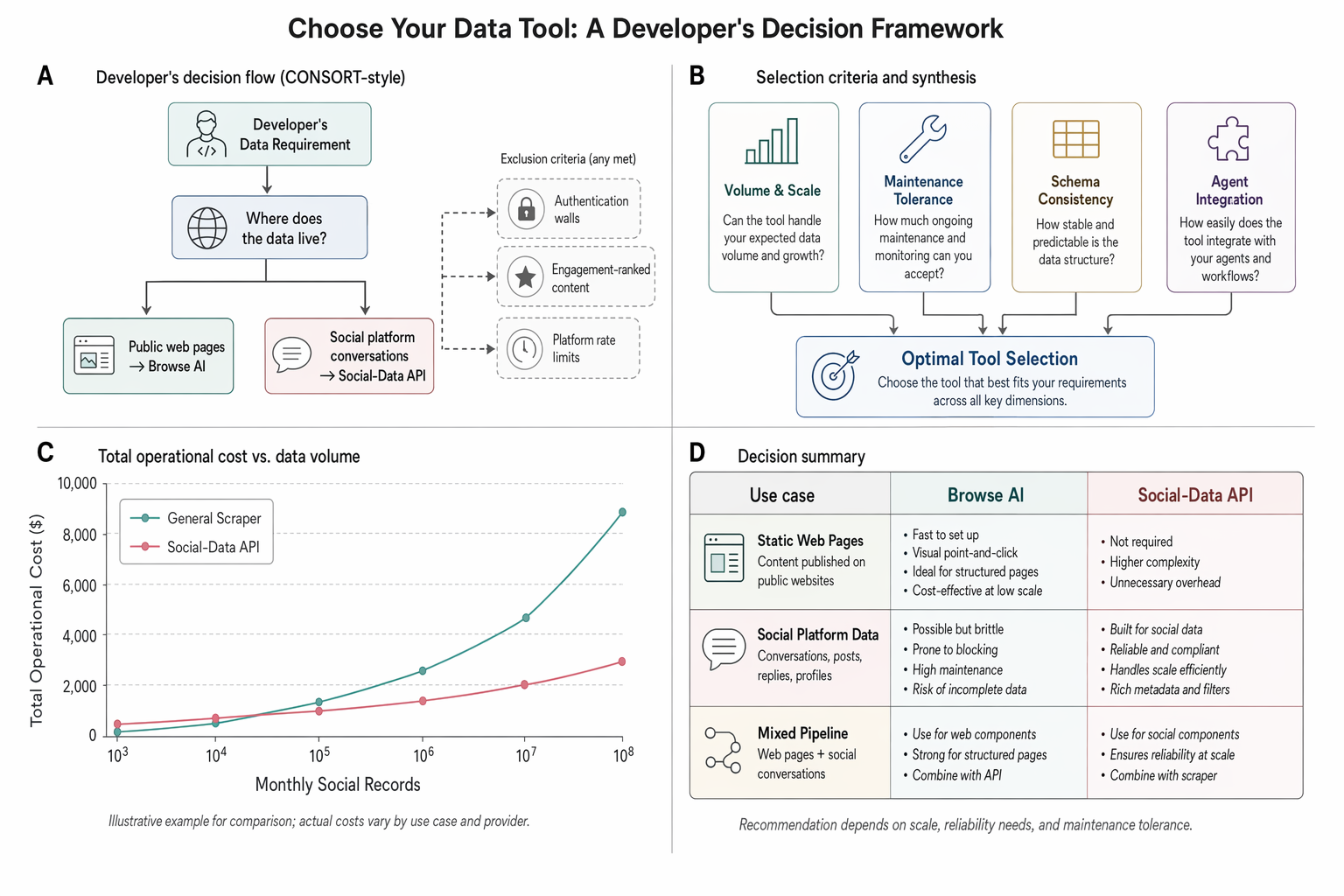
How do you choose between Browse AI and a social-data alternative for your stack?
Five questions narrow the decision quickly.
First, where does the data live? If most of it is on regular web pages, Browse AI. If most of it is inside Reddit, X, TikTok, Instagram, YouTube or any other social platform, a social-data API.
Second, how much volume do you need per month? Below a few thousand records, the credit pricing on Browse AI is competitive. Above tens of thousands of social records, a credits-never-expire model like SocialCrawl's Growth plan at 20,000 credits for £49 stops looking like a luxury and starts looking like the rational default.
Third, what is your tolerance for maintenance? Browse AI robots break when DOMs change. A managed API absorbs that maintenance internally. If you have one engineer covering the data pipeline, the managed option pays for itself the first time TikTok ships a layout change.
Fourth, do you need MCP or agent integration? If you are building agentic workflows in Claude, LangChain or any MCP-compatible host, an API that ships an MCP server out of the box (npx -y socialcrawl-mcp) collapses your integration step to a single command. Browse AI exposes a REST API; a social-data specialist exposes a tool that an agent can call directly.
Fifth, do you need a single envelope across platforms? If yes, that single decision is enough on its own. The cost of writing four normalisers and maintaining them in perpetuity is higher than any sensible API line item.
The global web scraping market sat at roughly $782.5 million in 2025 and is projected to hit $2.7 billion by 2035 at a 13.2% CAGR. The AI-driven slice alone is forecast to grow from $7.48 billion in 2025 to $10.2 billion in 2026. There is room for both general scrapers and platform specialists. The mistake is asking one to do the other's job.
Frequently asked questions
Is Browse AI good for scraping Reddit and TikTok at scale? Browse AI offers pre-built robots for Reddit and TikTok, but its credit-based pricing escalates quickly at scale. Extracting 10,000-plus rows per month on the Professional plan at $99 per month with 5,000 credits requires careful budgeting. For structured social data at production volume, purpose-built APIs are more cost-effective: TikTok alone has 26 dedicated endpoints in a single SocialCrawl integration.
What is the difference between a general web scraper and a social-data API? A general web scraper extracts HTML from any public URL and returns raw or lightly-structured content. A social-data API is purpose-built for specific platforms and returns structured records, posts, comments, engagement metrics and author profiles, with the anti-bot measures, rate limits and session handling already solved. The difference shows up most clearly in maintenance burden over time.
Can I use Browse AI as an alternative to official social media APIs? For light volume on publicly visible pages, yes. Browse AI can pull from public Reddit and TikTok pages without platform API keys. The limits show up at scale, behind logins, on private profiles, on NSFW or geo-restricted content, and whenever a platform changes its layout. Official or specialist social-data APIs are more reliable and ship richer metadata.
What happens when I need data from Reddit, X, TikTok and YouTube in the same pipeline? With general scrapers, you build a separate robot per platform, each with its own maintenance cycle. A unified social-data API queries all four through one envelope and one credential. SocialCrawl's universal search call hits 12 platforms in parallel for 20 credits, returning engagement-ranked results in one response.
Is social-media scraping legal in 2025? Scraping publicly available data is generally permitted in the US under the Ninth Circuit's hiQ v. LinkedIn ruling, and broadly in the EU subject to GDPR. The line gets crossed when you authenticate to bypass access controls, scrape personal data without a lawful basis, or breach a platform's explicit contractual terms. Read the platform terms of service and check applicable data-protection regulation before deploying at production scale.
Related posts

Naver Crawling in 2026: Blog, Cafe, and News via API
Three ways to crawl Naver in 2026: the official Naver Search Open API, your own HTML crawler, or one call to a unified API like SocialCrawl. Blog, cafe, news, and shopping, with code.

Python Social Media Crawling in 2026
Two ways to crawl social data with Python in 2026: build it yourself with requests and BeautifulSoup, or call a unified API with one httpx.get(). Here is when each one wins.

Best Time to Post on Social Media: 401 Posts Analyzed
Best time to post on social media: we analyzed 401 posts across TikTok, Instagram, YouTube, and Reddit. Posts at 20:00 UTC score +52% above the average.